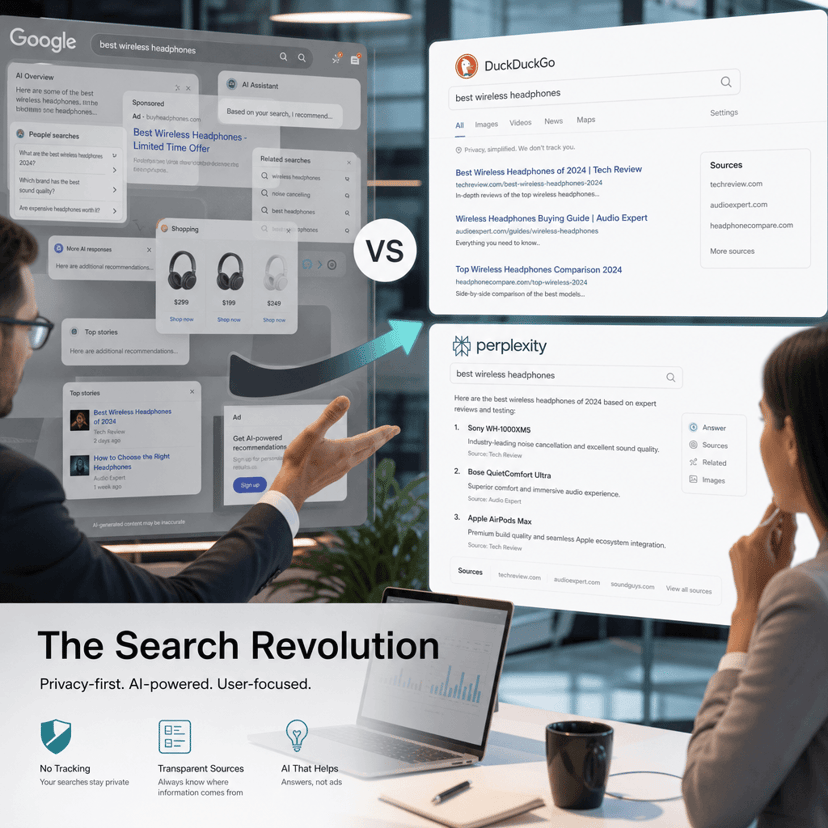
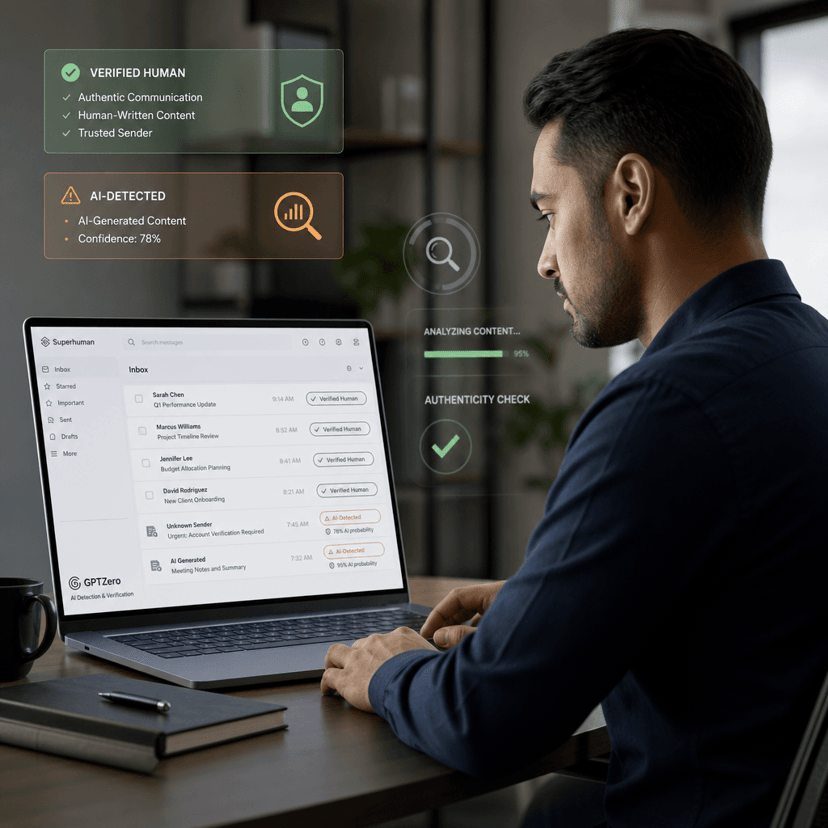
A quiet revolution is reshaping AI capabilities, but it's not happening everywhere at once. While OpenAI's GPT-5 and Google's Gemini 2.5 have transformed coding workflows seemingly overnight, other AI applications remain stubbornly stuck. The culprit? Reinforcement learning is creating winners and losers based on one critical factor: whether success can be measured automatically.
The AI industry is experiencing an uneven acceleration that's creating clear winners and losers across different capabilities. Russell Brandom's latest analysis for TechCrunch reveals a fundamental divide emerging between AI tasks that can leverage reinforcement learning and those that can't.
Coding applications are seeing breakthrough improvements almost monthly. Last week's release of Sonnet 2.4 continued a trend that began with OpenAI's GPT-5 and Google's Gemini 2.5, each making "a whole new set of developer tricks possible to automate," according to the report. But if you're using AI for email writing or general chatbot interactions, you're probably getting the same value you did a year ago.
The difference comes down to reinforcement learning's hunger for measurable outcomes. Software development offers billions of easily measurable tests - unit testing, integration testing, security testing - that have existed for decades. These pass-fail metrics can be repeated "billions of times without having to stop for human input," creating the perfect training environment for AI systems.
"There's no easy way to validate a well-written email or a good chatbot response," Brandom notes. "These skills are inherently subjective and harder to measure at scale." This creates what he calls the "reinforcement gap" - a growing divide between capabilities that can be automatically graded and those that require human judgment.
Google's senior director for dev tools recently confirmed that existing testing frameworks work just as well for validating AI-generated code as human-written code. But the implications extend far beyond software development. The reinforcement gap is becoming "one of the most important factors for what AI systems can and can't do."
Some processes are proving more testable than expected. OpenAI's surprise release of Sora 2 demonstrates dramatic improvements in AI-generated video. Objects no longer vanish randomly, faces maintain consistency, and physics laws are respected in both obvious and subtle ways. The improvements suggest OpenAI found ways to automatically test video quality through physics-based metrics.
"I suspect that, if you peeked behind the curtain, you'd find a robust reinforcement learning system for each of these qualities," Brandom writes. The breakthrough shows how creative companies can move tasks from the "hard to test" category into the reinforcement learning sweet spot.
The economic implications are staggering. Tasks that fall on the right side of the reinforcement gap will likely see successful automation, while those on the wrong side will see only incremental progress. "Anyone doing that work now may end up looking for a new career," the analysis warns.
Healthcare presents a particularly complex case study. Some medical processes might be easily measurable and ripe for automation, while others remain fundamentally subjective. "The question of which healthcare services are RL-trainable has enormous implications for the shape of the economy over the next 20 years."
Startups are already recognizing this divide. While general-purpose chatbots struggle to show meaningful improvement, specialized coding assistants are commanding premium pricing and rapid adoption. The pattern extends to accounting, where "a well-capitalized accounting startup could probably build" testing frameworks for financial reports from scratch.
The reinforcement gap isn't a permanent feature of AI development. It's "a result of the central role reinforcement learning is playing in AI development, which could easily change as models develop." But as long as RL remains the primary method for bringing AI products to market, the gap will only widen.
This creates a new lens for evaluating AI companies and their potential. Rather than asking whether a task can be automated, investors and entrepreneurs should ask whether success can be measured automatically at scale. The answer increasingly determines which AI applications will thrive and which will remain promising demos that never quite deliver transformational value.
The reinforcement gap is reshaping the AI landscape in ways that extend far beyond technology. It's creating a new hierarchy of automation potential based on measurability rather than complexity. As companies race to find ways to make subjective tasks more testable, and as new breakthroughs like Sora 2 prove some "impossible" problems aren't so impossible after all, we're entering an era where the ability to measure success automatically may be more valuable than the underlying skill itself. For workers, investors, and entrepreneurs, understanding which side of this gap your industry falls on isn't just strategic - it's existential.