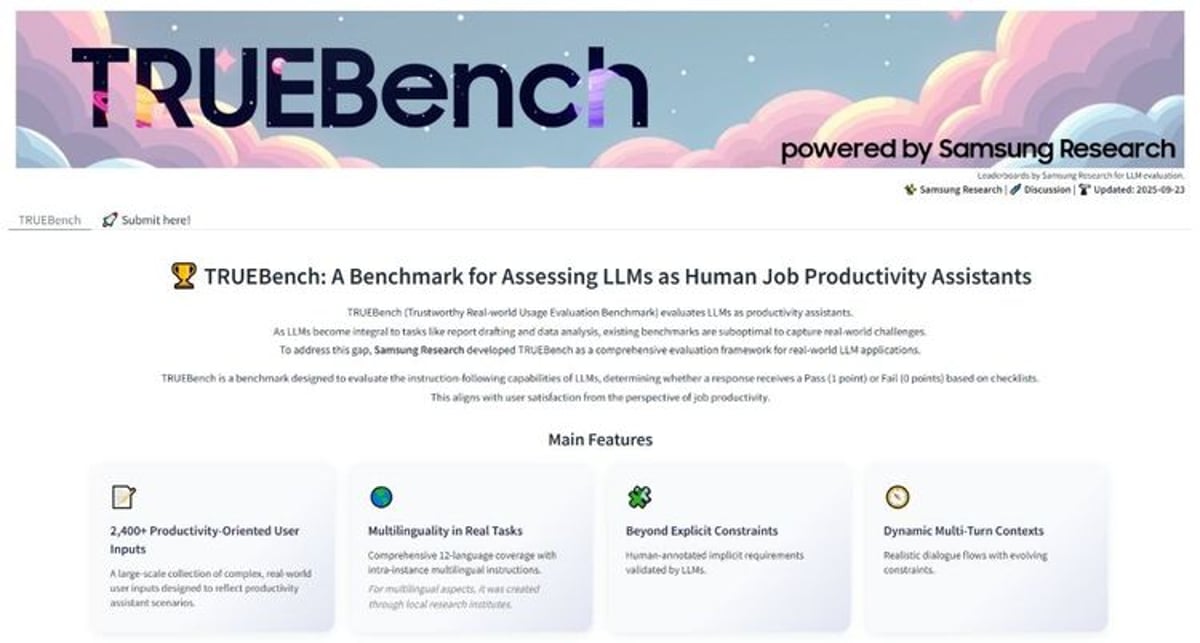
Samsung just dropped TRUEBench, a comprehensive AI benchmark that could reshape how we measure language model performance in actual workplace scenarios. Unlike existing benchmarks that focus on academic tests, TRUEBench evaluates AI across 2,485 real-world enterprise tasks spanning 12 languages - from quick content generation to complex document analysis. The move positions Samsung as a serious player in enterprise AI evaluation standards.
Samsung is making a bold play in the AI evaluation space with TRUEBench, a benchmark that actually tests what matters - how well AI performs in real workplace scenarios. The company's research division unveiled the platform today, targeting a glaring weakness in how we currently measure AI capability.
The timing couldn't be better. As enterprises rush to deploy AI tools, there's been a growing disconnect between impressive benchmark scores and actual workplace performance. Most existing benchmarks focus on academic problems or English-only scenarios that don't reflect the messy reality of global business operations.
"Samsung Research brings deep expertise and a competitive edge through its real-world AI experience," Samsung CTO Paul Kyungwhoon Cheun told reporters in the company announcement. "We expect TRUEBench to establish evaluation standards for productivity and solidify Samsung's technological leadership."
TRUEBench's scope is impressive - 2,485 test sets across 10 categories and 46 sub-categories, covering everything from content generation and data analysis to summarization and translation. The platform supports 12 languages including Chinese, Korean, Spanish, and Vietnamese, with cross-linguistic scenarios that mirror how global teams actually work.
What sets TRUEBench apart is its human-AI collaborative evaluation process. Human annotators create initial criteria, then AI systems review for errors and contradictions. The cycle repeats until evaluation standards reach precision levels that minimize subjective bias - a critical improvement over traditional benchmarks that rely heavily on human judgment.
The technical specs reveal Samsung's enterprise focus. Test scenarios range from 8-character micro-tasks to 20,000-character document processing, reflecting the full spectrum of workplace AI applications. Each test requires models to satisfy all conditions to pass, creating more granular performance metrics than simple pass-fail scores.
Samsung's decision to release TRUEBench on Hugging Face signals confidence in their evaluation methodology. The platform allows direct comparison of up to five models simultaneously, with performance and efficiency metrics displayed side-by-side. It's a move that invites scrutiny while positioning Samsung as a thought leader in enterprise AI evaluation.
The broader implications for the AI industry are significant. Current benchmarks like MMLU and HellaSwag measure general knowledge and reasoning but don't capture workplace-specific challenges like implicit user intent, multilingual context switching, or real-world document complexity. TRUEBench directly addresses these gaps.
For AI developers, TRUEBench provides a roadmap for enterprise-ready models. The benchmark's focus on productivity tasks - rather than academic puzzles - should drive development toward practical applications that businesses actually need. Companies evaluating AI tools now have a standardized way to assess real-world performance across languages and use cases.
The competitive landscape is already responding. With OpenAI, Google, and Microsoft racing to dominate enterprise AI, Samsung's benchmark could become the de facto standard for measuring business-relevant AI capability. The platform's multilingual focus also gives Samsung an edge in global markets where English-centric benchmarks fall short.
Samsung's TRUEBench represents a strategic shift from academic AI benchmarking toward practical workplace evaluation. By addressing critical gaps in multilingual support and real-world task complexity, the platform could become the industry standard for enterprise AI assessment. For businesses evaluating AI tools and developers building them, TRUEBench offers the first comprehensive framework for measuring what actually matters - productivity in diverse, real-world scenarios.