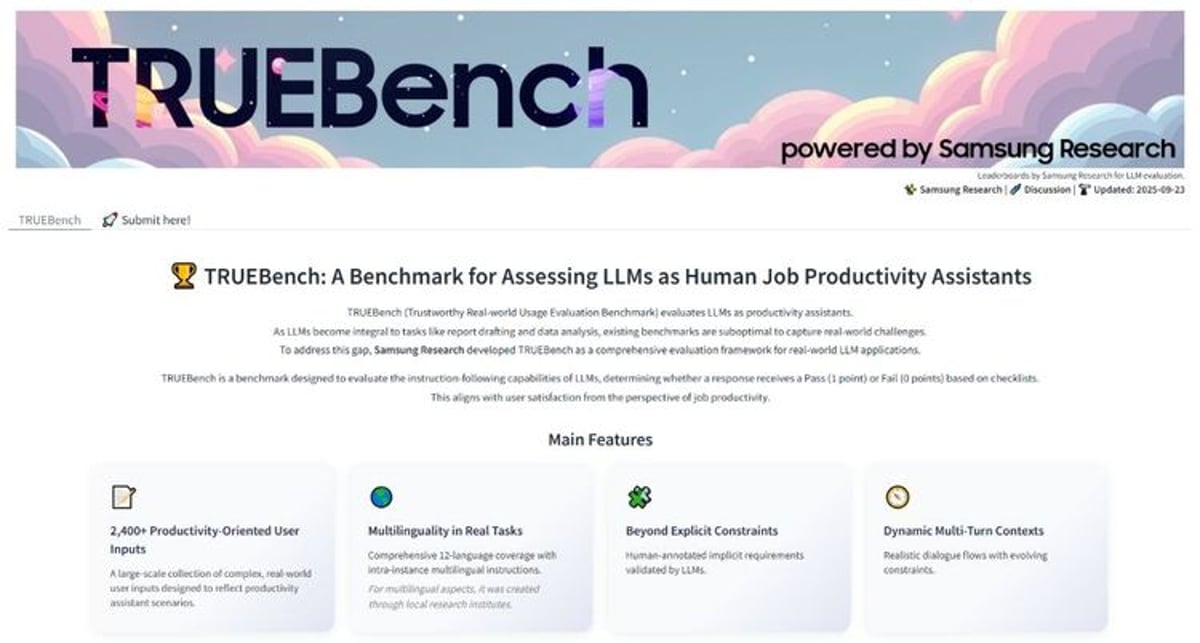
Samsung just threw down the gauntlet in AI evaluation. The tech giant's new TRUEBench benchmark directly challenges how the industry measures AI productivity, targeting real workplace scenarios across 12 languages that existing benchmarks largely ignore. With 2,485 test sets spanning everything from 8-character queries to 20,000-character document analysis, this isn't just another academic exercise - it's Samsung positioning itself as the arbiter of enterprise AI standards.
Samsung is making a bold play to reshape how we measure AI performance in the workplace. The company's newly unveiled TRUEBench benchmark doesn't just evaluate large language models - it directly challenges an industry that's been relying on outdated, English-centric testing that barely resembles real work environments.
The timing couldn't be more strategic. As enterprises rush to deploy AI across their operations, the gap between academic benchmarks and actual productivity has become glaringly obvious. Most existing evaluations focus on single-turn question-answer formats that miss the complex, multi-step workflows that define modern business operations.
"Samsung Research brings deep expertise and a competitive edge through its real-world AI experience," Paul Cheun, CTO of Samsung's DX Division, told Samsung Newsroom. "We expect TRUEBench to establish evaluation standards for productivity and solidify Samsung's technological leadership."
The numbers behind TRUEBench reveal Samsung's ambition. With 2,485 test sets spanning 12 languages - from Chinese and Korean to Vietnamese and Polish - the benchmark tackles the multilingual reality that global enterprises actually face. Test scenarios range from bite-sized 8-character requests to massive 20,000-character document summarization tasks, reflecting the true spectrum of workplace AI deployment.
But here's where Samsung gets clever: TRUEBench doesn't just measure accuracy. The benchmark evaluates implicit user needs - the unstated requirements that make or break real-world AI applications. It's the difference between an AI that technically answers a question correctly and one that actually solves the business problem at hand.
The evaluation methodology itself represents a significant departure from industry norms. Samsung Research developed a human-AI collaborative system where human annotators create initial evaluation criteria, AI systems review for errors and contradictions, then humans refine the standards through multiple iterations. This cross-verification process aims to eliminate the subjective bias that has plagued AI evaluation for years.
What makes this particularly interesting is Samsung's decision to make TRUEBench available on Hugging Face, the de facto standard for open-source AI model sharing. Users can compare up to five models simultaneously, with data on both performance and efficiency metrics - a direct shot at competitors who might prefer their evaluation methods stay proprietary.
The enterprise focus isn't accidental. Samsung has been quietly building its AI credentials through internal productivity deployments, giving the company real-world data that academic researchers and pure-play AI companies simply don't have. TRUEBench essentially weaponizes that experience, turning Samsung's internal learnings into industry-wide evaluation standards.
For AI model developers, this creates both opportunity and pressure. Companies that have optimized for existing benchmarks may find their models underperforming on Samsung's more nuanced, workplace-focused criteria. Conversely, models that excel at complex, multi-turn enterprise tasks could see their rankings improve significantly.
The multilingual aspect deserves particular attention. While English-centric evaluation has dominated AI benchmarks, the reality of global business demands systems that can seamlessly handle cross-linguistic scenarios. Samsung's inclusion of 12 languages, including support for cross-linguistic tasks, acknowledges what many international enterprises have learned the hard way - AI that works in English doesn't automatically work everywhere else.
This move also positions Samsung strategically against competitors like Google, Microsoft, and OpenAI who have been setting their own AI evaluation standards. By open-sourcing TRUEBench while maintaining control over its development, Samsung gains influence over how the industry measures AI progress without entirely giving up competitive advantage.
Samsung's TRUEBench launch represents more than just another AI benchmark - it's a strategic move to influence how the entire industry evaluates AI performance. By focusing on real-world enterprise scenarios and multilingual capabilities that existing benchmarks ignore, Samsung is positioning itself as the authority on practical AI evaluation. For businesses considering AI deployment, TRUEBench offers a more realistic preview of how models will actually perform in their operations. For AI developers, it creates new pressure to optimize for workplace productivity rather than academic metrics. The open-source availability ensures widespread adoption while Samsung maintains control over the standards that could define the next generation of enterprise AI.