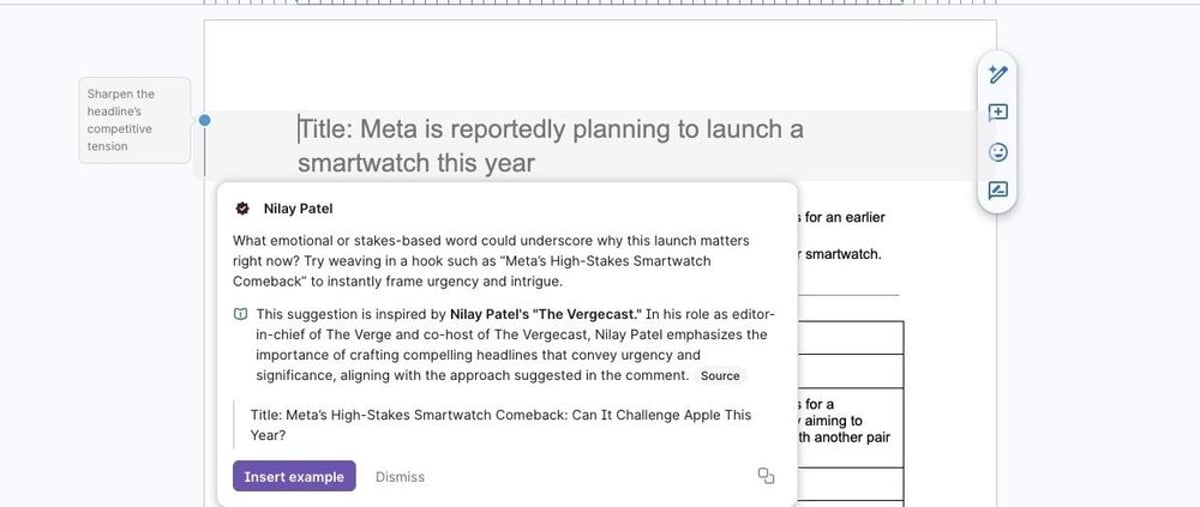
Grammarly is generating AI-powered writing feedback using real people's identities without their knowledge or consent. The Verge's Stevie Bonifield discovered the popular writing assistant's "expert review" feature impersonating her colleagues, including editor-in-chief Nilay Patel and senior editors David Pierce, Sean Hollister, and Tom Warren. None gave permission. The revelation, coming days after Wired reported the feature also mimics deceased professors, exposes a critical gap in how enterprise AI tools handle identity rights and consent.
Grammarly just landed itself in a consent crisis that could reshape how enterprise AI tools operate. The company's "expert review" feature is generating writing feedback using real people's names and professional identities without permission, turning AI assistance into an identity appropriation issue that has legal experts raising red flags.
The discovery came when The Verge reporter Stevie Bonifield tested the feature and found AI-generated comments appearing under her boss's name. Nilay Patel, The Verge's editor-in-chief, never consented to having his identity used to critique anyone's writing. Neither did colleagues David Pierce, Sean Hollister, or Tom Warren, all of whom appeared as "experts" in the system. According to Grammarly's support documentation, the feature offers feedback "inspired by" various subject matter experts, but the company apparently never bothered asking those experts for permission.
This isn't an isolated technical glitch. Wired reported Wednesday that Grammarly's system also impersonates deceased professors and other public figures. The feature, which launched in August 2025 as part of a broader push into specialized AI agents for students and professionals, appears to have scraped public writing samples to train models that mimic specific people's editorial styles.
The legal implications are staggering. Right of publicity laws in most U.S. states protect individuals from unauthorized commercial use of their identity, including their names and professional personas. California's statute explicitly covers digital simulations. By offering a premium feature that monetizes these identities, Grammarly may have crossed from fair use into commercial exploitation.
"This is exactly the kind of thing that's going to force courts to clarify what constitutes identity theft in the AI age," one intellectual property attorney told reporters covering the story. The question isn't whether Grammarly used public information (which it clearly did), but whether creating synthetic versions of real people for commercial purposes without consent violates their rights.
Grammarly has built its reputation on trust. The company serves over 30 million daily users, including enterprise customers who rely on the tool for sensitive business communications. The platform has access to countless documents, emails, and proprietary content. Discovering it's been quietly impersonating real people without disclosure raises questions about what other liberties the company might be taking with user data and public information.
The timing couldn't be worse for the enterprise SaaS sector. As companies race to embed AI features into existing products, many are discovering that moving fast and breaking things doesn't work when you're breaking consent laws. OpenAI faced similar backlash over voice cloning capabilities. Meta dealt with criticism about using public posts for training data. But Grammarly's case is more direct - it's not just training on someone's work, it's literally putting words in their mouth.
The incident exposes how quickly AI features can scale past ethical guardrails. Grammarly likely saw this as a value-add feature, giving users access to editorial perspectives from respected voices. But what feels like innovation from a product team looks like identity fraud from the outside. The company appears to have assumed that using public figures' professional personas constituted fair use, a legal theory that may not survive contact with actual lawyers.
Competitors are watching closely. Every writing assistant, content generation tool, and AI editor now faces questions about whose voices they're synthesizing and whether they have permission. The enterprise AI market, worth billions annually, depends on trust. One major lawsuit could trigger a wave of consent audits across the industry.
Grammarly has not yet issued a public statement addressing the revelations or explaining its legal reasoning for using real identities without consent. The company did not respond to requests for comment from The Verge. That silence is notable. Either Grammarly believes it has solid legal ground (unlikely given the backlash), or the company is scrambling to figure out how to unwind a feature that may have already violated hundreds or thousands of individuals' publicity rights.
This story also highlights how AI regulation is struggling to keep pace with deployment. There's no federal framework governing when companies can create synthetic versions of real people. State laws vary wildly. Europe's AI Act addresses some identity issues, but the U.S. remains a patchwork of protections that vary by jurisdiction. Grammarly may have inadvertently become the test case that forces legislative action.
For users, the lesson is stark - those helpful AI features may be more invasive than they appear. For companies building AI products, Grammarly just provided a masterclass in what not to do. And for the individuals whose identities were appropriated, the question becomes whether to pursue legal action or simply hope the feature gets quietly killed before more damage occurs.
Grammarly's identity appropriation scandal represents more than a PR crisis for one company. It's a watershed moment for the entire enterprise AI industry, forcing a reckoning with how synthetic personas intersect with individual rights. As AI tools become more sophisticated at mimicking human experts, the line between helpful feature and identity fraud grows dangerously thin. Without explicit consent frameworks, companies are gambling that innovation will outpace litigation. Grammarly just proved that's a losing bet. Expect legal action, regulatory scrutiny, and a industry-wide scramble to audit AI features for similar violations before the lawyers come knocking.